

Die Welt der künstlichen Intelligenz hat in den letzten Jahren erstaunliche Fortschritte gemacht. Das nach wie vor bekannteste Beispiel dafür ist ChatGPT, ein Modell, das in der Lage ist, menschenähnlichen Text in Form von Gesprächen zu generieren. In diesem Artikel sehen wir uns genauer an, wie ChatGPT und ähnliche Chatbots funktionieren und welche Technologien dahinter stecken.
Was ist ein Chatbot wie ChatGPT eigentlich genau?
Bei ChatGPT handelt es sich um eine generative, künstliche Intelligenz und ein sogenanntes LLM (Large Language Model = großes Sprachmodell). Der Chatbot ist, genauso wie seine Konkurrenz Bing Chat, Google Bard oder Claude, ein Produkt der Generative Pre-trained Transformer-Technologie, kurz GPT.
Entwickelt wurde ChatGPT von OpenAI, ist GPT eine bahnbrechende Architektur für neuronale Netzwerke, die es ermöglicht, auf Grundlage von riesigen Textdatensätzen (das komplette inkl. Wikipedia) menschenähnlichen Text zu erstellen. Das Besondere an ChatGPT (und auch allen anderen LLM) ist seine Fähigkeit, Kontextinformationen über lange Textabschnitte hinweg zu erfassen und zu nutzen. So kann man sich z.B. innerhalb eines Chats auf einen Text beziehen, den ChatGPT erstellt hat und diesen dann in eine andere Sprache übersetzen oder in einfacheren Worten verständlicher erklären lassen.
Was passiert, wenn man einem Chatbot eine Frage stellt?
ChatGPT verwendet Deep Learning, eine Untergruppe des maschinellen Lernens, um durch neuronale Transformer-Netzwerke menschenähnlichen Text zu erzeugen. Der Transformer sagt den Text, einschließlich des nächsten Worts, Satzes oder Absatzes, auf der Grundlage der typischen Sequenz seiner Trainingsdaten voraus.
Diese sogenannte Transformer-Architektur besteht aus mehreren Schichten von Aufmerksamkeitsmechanismen. Wird jetzt also eine Frage von einem User eingegeben, “analysiert” ChatGPT diese Frage nicht Wort für Wort, sondern der Aufmerksamkeitsmechanismus erkennt, welche Wörter in Beziehung zueinander stehen und wie sie gewichtet werden sollten, um den Kontext zu verstehen.

Was sind Token im Zusammenhang mit Chatbots?
ChatGPT teilt jeden Text, der ihm eingegeben wird, in sogenannte “Token” auf. Token sind ein zentraler Baustein in der Textverarbeitung von maschinellen Lernmodellen wie OpenAI’s ChatGPT und bilden die Grundlage für das Verständnis und die Interpretation von Textdaten. Diese Elemente, auch als Token bezeichnet, sind die kleinsten Einheiten, die solche Modelle verarbeiten können.
In der einfachsten Form kann ein Token ein einzelnes Wort, ein Satzzeichen oder ein Leerzeichen darstellen. Bei der Verarbeitung eines Textes wird dieser zunächst in eine Reihe von Token zerlegt. Dieser Vorgang wird Tokenisierung genannt. Das Modell verwendet dann die repräsentativen Zahlenwerte dieser Token zur Analyse und Vorhersage des Textes.
Ein wichtiger Aspekt dabei ist die Begrenzung der Anzahl der Token, die ein Modell verarbeiten kann. Bei GPT-3.5 Turbo liegt diese Grenze beispielsweise bei 4.096 Token und bei GPT-4 (der Bezahl-Version von ChatGPT) bei 8.192 Token. Dabei muss ein Token nicht unbedingt einem Wort entsprechen. Hier ist ein Beispiel, wie das Ganze aussieht:
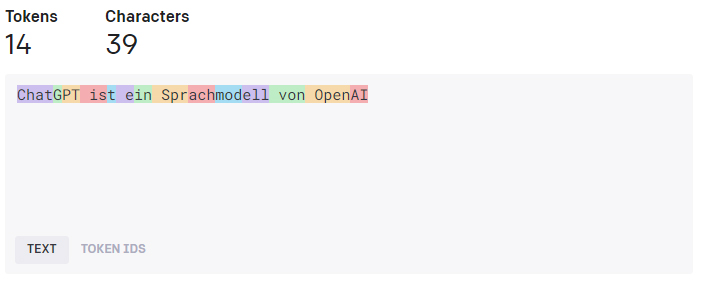
Der Text “ChatGPT ist ein Sprachmodell von OpenAI” besteht aus 39 Zeichen und ChatGPT “zerlegt” ihn in 14 Tokens, um ihn überhaupt “verstehen”, also verarbeiten zu können. Interessant dabei ist, dass der Chatbot lange deutsche Worte in mehrere Teile zerlegt. Je nach Sprache kann dann ein einzelnes Wort aus gleich vier Tokens zusammengesetzt sein, wie z.B. beim Wort “Sprachmodell”. Wer das selber ausprobieren will, kann das hier mit dem Tokenizer testen. 🙂
Wie “lernen” LLM?
Der Weg zur Fähigkeit, menschenähnlichen Text zu generieren, beginnt mit dem Vor-Training. Während dieses Schritts wird das Modell mithilfe einer riesigen Menge von Textdaten trainiert. Es erlernt dabei statistische Muster und Beziehungen zwischen Wörtern und Sätzen. Dies legt den Grundstein für das Verständnis von Syntax, Semantik und sogar weltlichem Wissen.
Nach dem Vor-Training folgt das Feintuning. Hier wird das Modell spezifisch auf die Aufgabe des Generierens von Gesprächstext abgestimmt. Es wird mit Dialogbeispielen trainiert, um die richtige Art der Interaktion zu erlernen. Diese Phase ermöglicht es dem Modell, menschenähnlichen Dialog zu simulieren. Mithilfe von Feedback in Form von menschliche Trainer werden Gespräche vorgegeben und die Antworten bewertet.
Dieses Training hilft einer LLM, die besten Antworten zu ermitteln. Um den Chatbot weiter zu trainieren, können die User*innen außerdem seine Antwort hoch- oder herunterstufen, indem sie auf die Symbole Daumen hoch oder Daumen runter neben der Antwort klicken. Die User*innen können auch zusätzliches schriftliches Feedback geben, um zukünftige Dialoge zu verbessern und zu verfeinern.

Auf diese Art und Weise lernten die „Maschine“ immer weiter und vor allem auch selbstständig. Das Machine Learning, zu Deutsch maschinelles Lernen, ist eine Technologie, die es Computern ermöglicht, aus Erfahrung zu lernen, ohne dass sie explizit programmiert werden müssen. Stell dir vor, du gibst einem Computer eine Menge Daten und sagst ihm, er solle Muster darin finden. Der Computer kann dann diese Muster nutzen, um Vorhersagen zu treffen oder Aufgaben zu erledigen, ohne dass man ihm jede einzelne Anweisung (vor)geben muss. Der Computer lernt also selbstständig, wie man bestimmte Dinge macht, indem er auf Daten und Erfahrungen zurückgreift.

Wie funktioniert ein LLM genau?

Massive Dataset:
Große Sprachmodelle werden mit riesigen Datensätzen trainiert, die aus Texten aus dem Internet, Büchern, Zeitungen und vielen anderen Quellen bestehen. Diese Daten dienen dazu, dem Modell eine breite Basis an Wissen und Sprachgebrauch beizubringen.
Deep Learning:
Diese Modelle nutzen tiefe neuronale Netzwerke, um Sprache zu verstehen und zu generieren. Deep Learning ist eine Methode des maschinellen Lernens, die große Mengen an Daten verarbeiten kann, um Muster zu erkennen und daraus zu lernen.
Transformer Architecture:
Diese spezielle Architektur ist besonders effektiv für die Verarbeitung von Sprache. Transformer-Modelle können Wörter im Kontext besser verstehen, indem sie Beziehungen zwischen allen Wörtern in einem Satz oder Textabschnitt betrachten, unabhängig von deren Position.
Self-supervised Learning:
Im Gegensatz zum überwachten Lernen, wo Modelle mit klaren Anweisungen (wie korrekte Antworten) trainiert werden, lernt ein selbstüberwachtes Modell durch die Analyse von Daten und das Erkennen von Zusammenhängen ohne spezifische Anleitung. Das Modell versucht, Teile des Eingabetexts vorherzusagen oder zu rekonstruieren, was ein tiefes Verständnis der Sprache fördert.
Fine-tuning:
Nachdem das Modell mit allgemeinen Daten vortrainiert wurde, kann es für spezifische Aufgaben oder auf spezifische Datensätze „feinabgestimmt“ werden. Dabei wird das Modell weiter trainiert (meist mit weniger Daten), um es auf eine bestimmte Anwendung oder ein spezifisches Problem besser anzupassen.
LLMs sind das Herzstück der fortschrittlichsten Chatbots und ermöglichen eine nahtlose, natürliche Kommunikation zwischen Mensch und Maschine. Auch virtuelle Assistenten wie Siri oder Alexa verwenden große Sprachmodelle, um natürliche Sprachanfragen zu verstehen und darauf zu reagieren. Große Sprachmodelle sind ein Produkt des tiefen Lernens und Teil des breiteren Feldes der Künstlichen Intelligenz.
Antworten von Chatbots mit Vorsicht genießen!
Der faszinierendste Teil von ChatGPT ist seine Fähigkeit zur Interaktion. Gibt man dem Programm eine Texteingabe, dann antwortet es mit Text, der auf dem erlernten Wissen und dem Muster aus dem Training basiert. Die vorherigen Eingaben dienen als Kontext, um angemessene Antworten zu generieren.
Aber Vorsicht: Das Modell kann fehlerhafte oder unangemessene Antworten liefern, da es auf vorherigen Textdaten basiert. Insbesondere, wenn es um Informationen und Fakten geht, sollte sicherheitshalber immer gegengeprüft werden. Ein Warnhinweis auf der Startseite weist auf Falschinformationen hin, die der Chatbot geben könnte. Das Modell kann Schwierigkeiten haben, lange Zusammenhänge im Text zu erfassen, und neigt dazu, auf vorherigen Mustern zu basieren, anstatt tatsächliches Verständnis zu zeigen. Es kann auch dazu neigen, ungenaue oder veraltete Informationen wiederzugeben.
Dennoch arbeiten die Entwickler der Chatbots unermüdlich daran, die Leistung ihrer Modelle zu verbessern. Durch kontinuierliches Training, mit neuen Daten und fortschrittlichen Techniken zur Kontextverarbeitung werden die Chatbots laufend verfeinert.
Fazit
ChatGPT und Co zeigen eindrucksvoll, wie künstliche Intelligenz in der Lage ist, menschenähnlichen Text zu generieren und interaktive Gespräche zu simulieren. Sie offenbaren die Macht der Kombination aus Vor-Training, Feintuning und Nutzer*innen-Feedback in der Welt der neuronalen Netzwerke. Wenn man weiß, wie diese Sprachmodelle zu ihren Antworten kommen, wirkt alles gleich viel weniger “magisch”, aber trotzdem ist es extrem beeindruckend.
Quellen:
– https://www.computerweekly.com/de/definition/ChatGPT
– https://www.moin.ai/chatbot-lexikon/chatgpt-chatbot
– https://chatgptx.de/blog/token
– https://platform.openai.com/tokenizer


